Inside Our Automated Weekly Tech Briefing, Powered by n8n
Collecting, summarizing, and delivering the week's most relevant tech news, without anyone reading a single article.

The problem: Staying informed without drowning in feeds
Technology moves fast, but trying to keep up is costing us. The average knowledge worker spends 28% of their workweek on email, that's over 11 hours every week just managing messages. Meanwhile, an estimated 2 million new articles hit the internet every single day.
For a team that builds technology, staying current is not optional. But the way most people do it is broken. Someone opens Hacker News during lunch. Someone else skims Ars Technica between meetings. A third person subscribes to a newsletter they read inconsistently. The result is fragmented awareness: everyone has seen different things, no one has the full picture, and there is no shared baseline of what happened this week.
The alternative, systematically reading multiple sources every day is not realistic either. The volume is too high, the signal-to-noise ratio too low, and the time cost too steep for anyone with actual work to do.
We wanted a system that solves both problems at once: comprehensive coverage across multiple sources, distilled into a single briefing that the entire team can read in minutes.
What we built
Every Sunday morning, before anyone on the team opens their laptop, the Weekly Tech Briefing System has already collected articles from four distinct news sources, extracted the full content, generated a structured HTML briefing using AI, and delivered it by email. No one curates it. No one edits it. It simply arrives, ready to read.
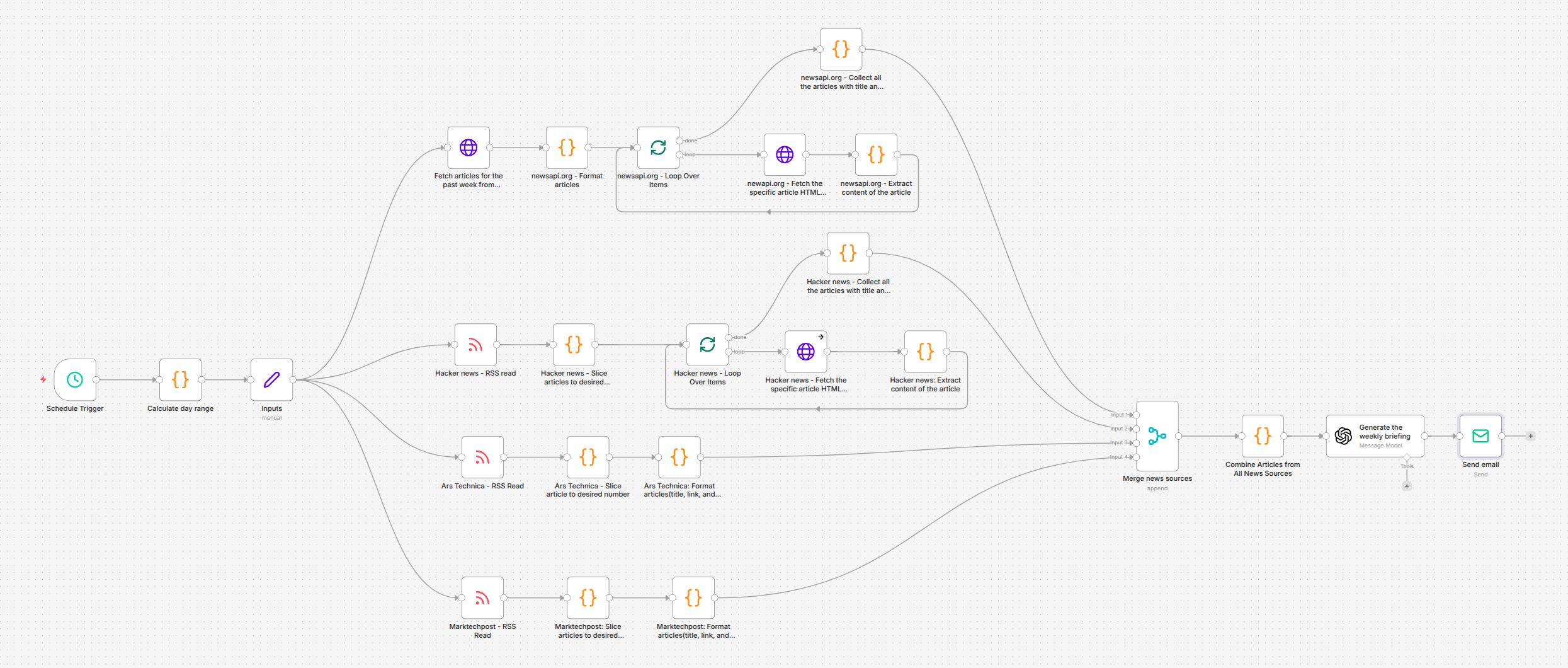 Image 1 - The weekly briefing pipeline
Image 1 - The weekly briefing pipeline
The system handles three distinct jobs:
1. Collects articles from four independent sources
The pipeline pulls from a deliberately diverse set of sources, each covering a different slice of the tech landscape:
| Source | What It Covers | Collection Method |
| NewsAPI | Broad technology news across major publications | Search API with relevance ranking |
| Hacker News | Developer-focused stories and technical discussions | RSS feed |
| Ars Technica | In-depth technology and IT reporting | RSS feed |
| MarkTechPost | AI and machine learning research coverage | RSS feed |
For each source, the system fetches the top articles from the past seven days. The date range is calculated dynamically based on the scheduled run date, so the briefing always covers exactly one week of content with no gaps and no overlap.
2. Extracts and processes full article content
Headlines and metadata are not enough to generate meaningful summaries. The system goes a step further: for each article, it fetches the full HTML page from the source URL and extracts the actual text content.
The extraction is designed to handle the inconsistency of the real web. It strips scripts, styles, and ads, then looks for content within semantic HTML tags falling back gracefully when sites use non-standard structures. Each article's content is captured alongside its title and source link, ready for summarization.
3. Generates a single, structured weekly briefing
Once all articles from all four sources are collected and merged, the full set is passed to an AI model in a single call. The model generates a formatted HTML briefing with a strict structure: a one-sentence introduction, then for each article a title, a link to the original, a two-sentence summary, and two key takeaways, followed by a one-sentence conclusion.
The constraint on format is deliberate. Two sentences and two bullet points per article keeps the briefing scannable. Including the original link for every article means anyone who wants depth can click through. The result is a briefing that respects the reader's time while covering the full breadth of the week's news.
The finished HTML is delivered by email to the team automatically.
How the pipeline works
The workflow runs as a 25-node scheduled pipeline in n8n. Unlike our event-driven systems that respond to incoming triggers, this one operates on a clock executing every Sunday morning and covering the previous seven days.
Schedule and date calculation - A schedule trigger fires weekly. A code node calculates the exact date range for the past week, ensuring each briefing covers precisely seven days of content regardless of when the workflow actually executes.
Parallel source collection - The pipeline branches into four parallel paths, one per news source. NewsAPI is queried via its search endpoint with relevance ranking and language filtering. Hacker News, Ars Technica, and MarkTechPost are collected via their RSS feeds. Each source returns a configurable number of articles currently set to five per source, yielding up to twenty articles per briefing.
Content extraction - For sources that return only metadata (NewsAPI, Hacker News), the pipeline loops through each article, fetches the full HTML page, and extracts the readable text content. RSS sources that include content in their feeds (Ars Technica, MarkTechPost) skip the fetch step and go straight to formatting. Content is capped at 5,000 characters per article to balance thoroughness with processing cost.
Source merging - The four parallel branches converge into a single merge node, combining all articles into one unified array. Each entry carries its title, extracted content, and source link.
AI briefing generation - The merged article set is passed to GPT-4o with a tightly constrained prompt. The model produces a complete HTML briefing following a fixed structure ensuring every article is included and every summary is concise. The strict formatting rules prevent the model from editorializing or expanding beyond what the reader needs.
Email delivery - The generated HTML is sent via SMTP to the distribution list. The briefing arrives formatted and ready to read no further processing or manual formatting required.
The difference it makes
The briefing has shipped every Sunday since deployment without a single missed week.
Before: Team members independently checked different news sources at different times throughout the week. Some articles were seen by everyone, most were seen by no one, and there was no shared awareness of what was happening in the broader tech landscape. Staying informed depended on individual discipline and available time both unreliable.
After: Every Sunday morning, the entire team receives the same curated briefing covering four major sources. By Monday's first meeting, everyone has a shared baseline: the same articles, the same summaries, the same takeaways.
What this changed in practice:
- Shared context replaced fragmented browsing - the team discusses the same developments because they all read the same briefing.
- Zero ongoing effort - no one curates, edits, or sends the briefing. It arrives automatically, every week, without fail.
- Breadth without the time cost - twenty articles across four sources, summarized into a briefing that takes five minutes to read. The equivalent manual effort would consume hours.
- Every summary links to the original - when an article warrants deeper reading, the source is one click away. The briefing is a starting point, not a dead end.
What comes next
The weekly cadence and four-source setup is a solid baseline. There are several natural directions to extend it:
- Source expansion - adding domain-specific feeds, academic preprint trackers, or competitor blog monitoring to broaden coverage based on what the team finds most valuable.
- Personalized briefings - generating different briefing variants for different roles: a deeper AI research focus for the engineering team, a market-oriented version for the business team.
- Slack and Teams delivery - posting the briefing to team channels in addition to email, meeting people where they already work.
- Trend detection across weeks - comparing consecutive briefings to surface recurring themes and emerging patterns that a single week's snapshot would miss.
- Sentiment and urgency tagging - flagging articles that signal competitive threats, regulatory changes, or breaking developments that warrant immediate attention rather than weekly review.
Key takeaway
Information overload is not a content problem it is a curation problem. The raw material is abundant. What teams lack is a reliable, consistent process that turns that raw material into something useful without consuming the very time it is supposed to save.
The Weekly Tech Briefing System solves this by running the same disciplined process every week: collect from diverse sources, extract the substance, summarize with strict constraints, and deliver on schedule. No one needs to remember to check anything. No article slips through because someone was busy. The team stays informed by default, not by effort.