Apribojimų pavertimas galimybėmis: anomalijų aptikimas be priežiūros
Ar kada nors susimąstėte, kaip išmokyti modelį aptikti anomalijas? Anomalijų aptikimo srityje, ypač tokiose sudėtingose sistemose kaip "Kubernetes", retų anomalijų aptikimas turint ribotą pavyzdžių skaičių yra klasikinis iššūkis.
Tačiau ar galite įsivaizduoti atvejį, kai turite duomenų rinkinį, kuriame anomalijų yra mažiau nei 0,5 %, jūsų užduotis - sukurti modelį, kuris aptiktų tas 0,5 % anomalijų, ir, svarbiausia, negalite naudoti pateiktų anomalijų ML modeliams mokyti?
Dirbtinės anomalijos
Mūsų projektas susidūrė su tokia dilema: nepakanka anomalinių duomenų - iš esmės jų nėra - kad galėtume veiksmingai apmokyti prižiūrimus modelius. Sprendimas? Nusprendėme patys sugadinti duomenis - sugeneruoti savo anomalijas. Modeliuodami įvairių tipų anomalijas, pavyzdžiui, ekstremalias reikšmes ar neįprastus modelius "Kubernetes" klasteriuose, galėjome išmokyti savo modelius, ko ieškoti.
Mokymas
Idėja yra apmokyti modelį naudojant realius įprastus atvejus ir sugeneruotas anomalijas. Tada išbandyti modelį su tikromis anomalijomis ir palyginti jo veikimą su sugeneruotomis ir tikromis anomalijomis. Idealiu atveju jie turėtų sutapti. Arba gali būti ir taip, kad sugeneruotų anomalijų rezultatai bus šiek tiek prastesni: tai reikš, kad sugeneruotas anomalijas bus sunkiau stebėti, todėl modelis bus patikimesnis realiame pasaulyje.
Anomalijų kūrimas
Nustatėme įvairių tipų anomalijų - kai kurios buvo paprastos, pavyzdžiui, itin dideli naudojimo šuoliai, o kitos - sudėtingos, pavyzdžiui, subtilios, tačiau neįprastos išteklių užklausų sekos, galinčios rodyti gilesnes problemas. Tai yra apytikslis anomalijų, kurias tyrėme ir naudojome savo sprendime, tipų sąrašas:
Ekstremaliųjų verčių anomalijos: Tai reikšmės, kurios yra gerokai didesnės arba mažesnės už normą. Šio tipo anomalijos paprastai naudojamos modeliuojant scenarijus, kai staiga smarkiai padidėja arba sumažėja duomenų rodikliai, pvz., procesoriaus ar atminties naudojimas.
Anomalijos pagal modelį: Anomalijos, kurios pažeidžia įprastą įvykių modelį ar seką. Tai gali būti neįprastos sistemos iškvietimų sekos arba netipiniai tinklo srauto modeliai, kurie gali rodyti sudėtingas atakas arba sistemos veikimo sutrikimus.
Kontekstinės anomalijos: Tai situacijos, kai duomenų taškai yra anomalūs tam tikrame kontekste, tačiau kitoje aplinkoje jie gali nebūti nukrypimai. Pavyzdžiui, didelis atminties naudojimas gali būti normalus dienos metu, bet gali būti laikomas anomaliu, jei tai vyksta naktį.
Kolektyvinės anomalijos: Tai įvyksta tada, kai susijusių duomenų taškų rinkinys yra anomalus, palyginti su visu duomenų rinkiniu. Tai gali būti panašių neįprastų įvykių grupės, pavyzdžiui, pasikartojantys prisijungimo sutrikimai iš to paties IP adreso per trumpą laiką.
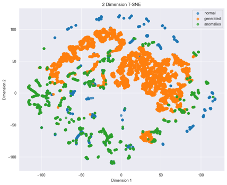
Svarbiausia, kad anomalijos būtų kuo panašesnės į tikras anomalijas. Taip pat labai rekomenduojame naudoti t-SNE, PCA ar kitus matmenų mažinimo ir vizualizavimo metodus, kad pamatytumėte, kaip tiesiškai ar netiesiškai galima atskirti normalias ir realias anomalijas bei sugeneruotas anomalijas.

“Gaussian” prognozės
Be tradicinių mašininio mokymosi modelių, ištyrėme ir “Gaussian” prognozavimo modelį. Šis paprastas statistinis modelis, stebėtinai veiksmingas, naudojo pagrindines prielaidas apie duomenų normalumą, kad nustatytų nukrypimus. Nors dėl mažesnio tikslumo tai nebuvo galutinis sprendimas, jis pasirodė esąs neįkainojamas greitiems patikrinimams ir preliminariems vertinimams. Siūlome pirmiausia išbandyti paprastus modelius, nes jų našumas gali suteikti užuominų sudėtingesniems ML algoritmams mokyti. Gali būti net taip, kad tokie paprasti modeliai, kaip "Gaussian Predictor", bus pranašesni už ML algoritmus ir taps jūsų galutiniu sprendimu.
Išvada
Šis projektas parodė, kad kartais raktas į sudėtingų duomenų mokslo problemų sprendimą yra toks paprastas, kaip tik permąstyti turimus išteklius - apribojimus paversti inovacijų galimybėmis. Kūrybiškai generuodami savo pačių anomalijas, galėjome apmokyti prižiūrimus anomalijų aptikimo modelius be realių etikečių mokymui, pasiekdami gana aukštą tikslumą ir atšaukimą. Šis metodas ne tik išsprendė mūsų pradinę duomenų stygiaus problemą, bet ir suteikė keičiamo mastelio metodą modeliams mokyti įvairiuose scenarijuose, kuriuose trūksta konkrečių anomalijų pavyzdžių.
Reikia pagalbos su modeliu? Ieškote individualaus sprendimo savo įmonei? Susisiekite su mūsų komanda ir kartu ištirkime galimybes.